今回は、7つのスタッツを使って、NBAプレイヤー間のスタッツにおける類似性を統計ソフトRを用いて確認していきたいと思います。
データは、2022-23レギュラーシーズンのPbox(過去記事参照)を使用します。
まずは、今回の分析手法として採用される、多次元尺度構成法のおおまかな内容から見ていきます。
※データ分析を実践する際に参考にしている書籍『Basketball Data Science: With Applications in R』の紹介記事も書きましたので、よろしければご確認ください。

多次元尺度構成法
多次元尺度構成法とは、対象となるデータ間の(非)類似度が与えられたとき、その(非)類似度に基づいて、それぞれのデータの位置をマップ上に表現する手法です。
多次元尺度構成法はMDS(Multi-Dimensional Scaling)とも呼ばれています。
対象となるデータがマップ上にプロットされる際には、類似したものは近くに配置され、類似していないものは遠くに配置されます。
今回の場合は、7つのスタッツをもとに類似度が示され、スタッツの成績が似ているプレイヤーほど近くに配置され、スタッツの成績が似ていないプレイヤーほど遠くに配置されることになります。
そのため、プレイヤー間の位置から、その関係性を視覚的に把握することができるようになります。
※多次元尺度構成法に関する理論的背景などの詳細は、他ウェブサイトにて参照いただくようお願いします。
NBAプレイヤーのスタッツをもとに多次元尺度構成法によるマップを作成<2022-23レギュラーシーズン>
多次元尺度構成法によるNBAプレイヤーのマップ<ジャームズ・ハーデンとステフィン・カリーの類似性が高い>
多次元尺度構成法によるプレイヤーのマップは、下記のとおりです。
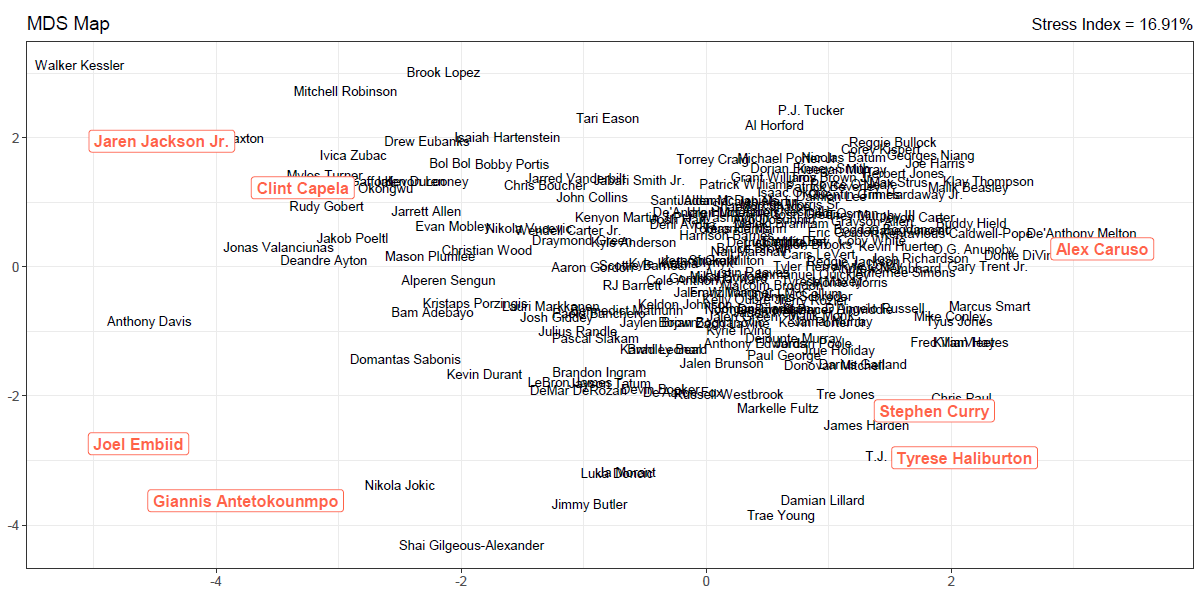
上記のマップを作成するにあたり使用したスタッツは、P2M(2Pシュート成功数)、P3M(3Pシュート成功数)、FTM(フリースロー成功数)、REB(リバウンド数)、AST(アシスト数)、STL(スティール数)、BLK(ブロック数)となっています。
各スタッツはMIN(分)あたりの数値に変換したデータを使用しており、プレイヤーに関しては、MINが1,500MIN以上のプレイヤーを抽出しています。
上記のマップ上では、この7つのスタッツ成績が似ているプレイヤー同士が近くに配置される一方で、スタッツ成績が似ていないプレイヤーほど遠くに配置されることになります。
また、マップ上では各スタッツのトップの7プレイヤーを赤色のハイライトで示しています。
各スタッツのトッププレイヤーは、P2Mはヤニス・アデトクンボ、P3Mはステフィン・カリー、FTMはジョエル・エンビード、REBはクリント・カペラ、ASTはタイリース・ハリバートン、STLはアレックス・カルーソ、BLKはジャレン・ジャクソンJr.となっています(NBA公式ウェブサイトのスタッツを参照しています)。
また、マップに記されている横軸、縦軸の数値は特に意味を持っておらず、各プレイヤー間の位置関係に注目していくことになります。
なお、マップの右上に記載されているストレス値とは、多次元尺度構成法により表現したマップの当てはまりの良さを示す指標で、このストレス値が小さいほどマップの再現性が高いと評価されます。
具体的なストレス値の目安は、0が「完全に適合」、0.025は「非常に良い適合」、0.050は「良い適合」、0.100は「悪くはない適合」、0.200は「良くない適合」とされています。※1
※1 Kruskal, J.B. (1964), Multidimensional scaling by optimizing goodness of fit to a nonmetric hypothesis, Psychometrika, Vol. 29, p1–27. および永田 靖、棟近 雅彦(2001)「多変量解析法入門」サイエンス社, p167-168.を参照しています。
今回のストレス値は16.91%であり、「悪くはない適合」と「良くない適合」の中間ぐらいの適合度となっています。
マップを確認すると、類似性が高いプレイヤーが集中しているエリアが右側にあることが分かります。(プレイヤーが集中し判別が出来なくなっているため、参考のために該当エリアの拡大版を後ろのほうに載せています。)
プレイヤーが集中している右側のエリアから左側へ目を向けると、放射線状に各プレイヤーが配置されていることが確認でき、その位置関係によりプレイヤー間の類似性を読み取ることができます。
例えば、デイミアン・リラードとトレイ・ヤング、ジャームズ・ハーデンとステフィン・カリー、ルカ・ドンチッチとジャ・モラントはその位置関係が近いことから、スタッツ成績が似ているプレイヤーとして挙げることができます。
一方、アンソニー・デイビスやウォーカー・ケスラーは、近くに他プレイヤーが配置されていないことから、スタッツ成績が特有のプレイヤーであることが判断できます。
さらに、各スタッツのトップの7プレイヤーに関しては、比較的4方向に分かれて配置されていることも分かります。
次に、マップ上の各プレイヤーの位置を解釈しやすくするために、各スタッツの成績に関して、等高線の形式で表現されたヒートマップを示したいと思います。
※【参考】プレイヤーが集中し判別できないエリアの拡大版です。
なお、上記で示したマップを出力するためのコマンドは、下記のとおりです。
> library(BasketballAnalyzeR) #パッケージBasketballAnalyzeRの読み込み
> Pbox2223 <- read.csv(file="Pbox_2223.csv") # Pbox2223の読み込み
> attach(Pbox2223) #attach関数でPbox2223を指定
> data2223 <- data.frame(P2M, P3M, FTM, REB=(OREB+DREB), AST, STL, BLK)/MIN #各スタッツのMINあたりの数値をdata.frame関数でまとめてdata2223に格納
> detach(Pbox2223) #detach関数でPbox2223を指定から外す
> data2223 <- subset(data2223, Pbox2223$MIN>=1500) #data2223から出場時間1500MIN以上のプレイヤーを抽出
> id <- Pbox2223$Player[Pbox2223$MIN>=1500] #1500MIN以上のプレイヤーをPbox2223から抽出し、idに格納
> mds <- MDSmap(data2223) #MDSmap関数によりデータの座標とストレス値を求める
> selp <- which(id=="Giannis Antetokounmpo" | id=="Stephen Curry" | id=="Joel Embiid" | id=="Clint Capela" | id=="Tyrese Haliburton" | id=="Alex Caruso" | id=="Jaren Jackson Jr.")
#各スタッツのトップのプレイヤーをselpへ格納
> plot(mds, labels=id, subset=selp, col.subset="tomato") #mdsのマップをプロットし、selpの7プレイヤーを赤色でハイライトする
> plot(mds, labels=id, subset=selp, col.subset="tomato", zoom=c(-1,2,-2,2)) #横軸の-1~2、縦軸-2~2のエリアを拡大する等高線形式のヒートマップによるマップ配置の解釈<エンビード、ヤニス、カリー、ハリバートンはオフェンスでの貢献が大きい>
各スタッツに関する等高線形式で表現されたヒートマップは、下記のとおりです。
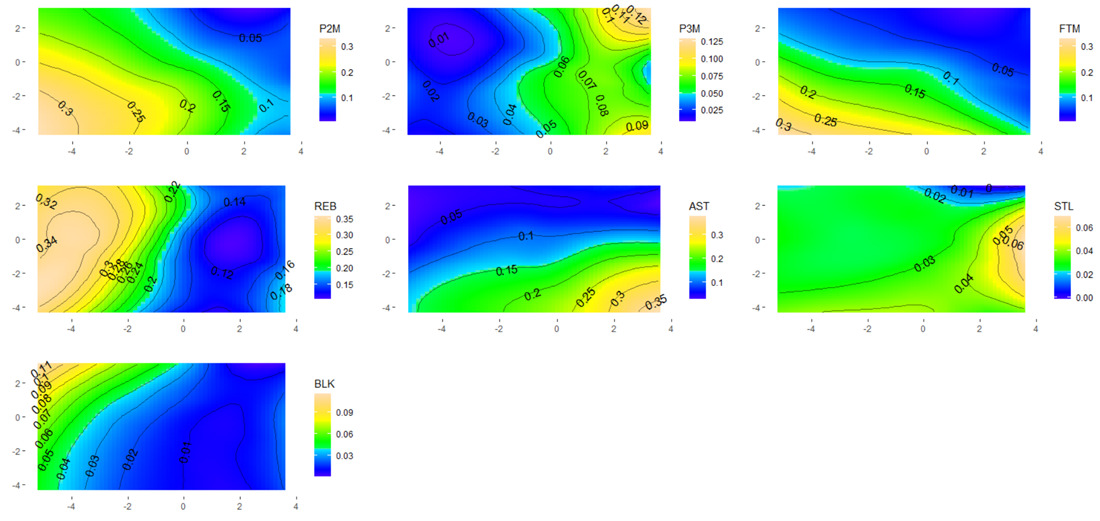
上記のヒートマップでは、スタッツ数が低ければ青色で表示され、反対にスタッツ数が高ければ薄黄色で表示されます。
また、等高線により特定のスタッツ数を有するプレイヤーが、どのエリアに配置されているのかを把握することができます。
上記のヒートマップを確認すると、各スタッツにつき以下の点を読み取ることが出来ます。
- P2M:スタッツが高水準のプレイヤーは左下エリアに配置される。
- P3M:スタッツが高水準のプレイヤーは右上と右下のエリアに配置される。
- FTM:スタッツが高水準のプレイヤーは左下エリアに配置される。
- REB:スタッツが高水準のプレイヤーは左端の中央付近エリアに配置される。
- AST:スタッツが高水準のプレイヤーは右下エリアに配置される。
- STL:スタッツが高水準のプレイヤーは右端の中央付近エリアに配置される。
- BLK:スタッツが高水準のプレイヤーは左上エリアに配置される。
これらを考慮すると、マップ上のプレイヤーの配置に関する解釈の1つとして、以下のような解釈の仕方を挙げることができます。
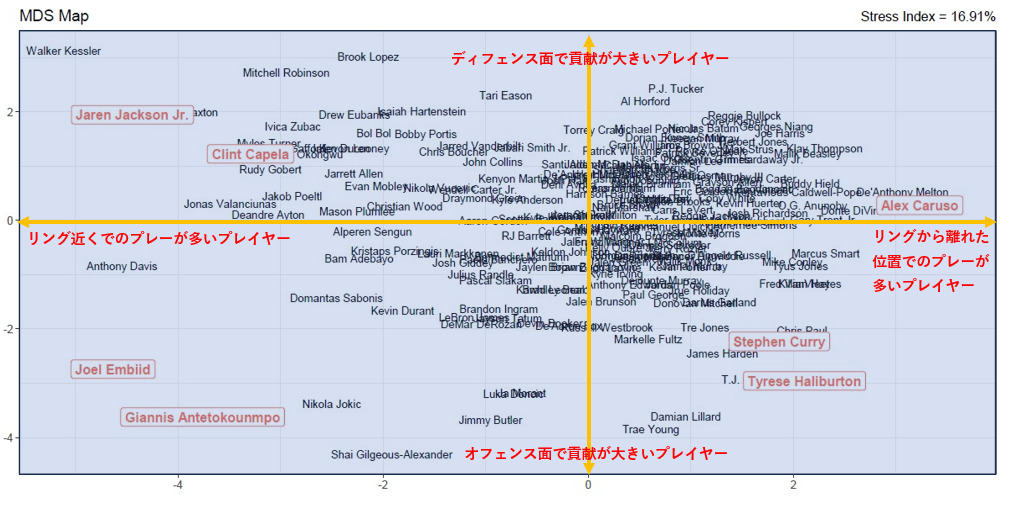
各スタッツのトッププレイヤーを例にとれば、エンビードとヤニス・アデトクンボは比較的リングの近くでプレーし、オフェンス面での貢献が大きいと解釈でき、また、アレックス・カルーソは比較的リングから離れた位置でプレーし、ディフェンス面での貢献が大きいと捉えることができます。
同様に、カリーとハリバートンは比較的リングから離れた位置でプレーし、オフェンス面での貢献が大きいと解釈でき、また、ジャレン・ジャクソンJr.とクリント・カペラは比較的リングの近くでプレーし、ディフェンス面での貢献が大きいと捉えることができます。
なお、上記で示したヒートマップを出力するためのコマンドは、下記のとおりです。
> plot(mds, z.var=c("P2M", "P3M", "FTM", "REB", "AST", "STL", "BLK"), contour=TRUE, palette=topo.colors)
#各スタッツの等高線形式のヒートマップを出力おわりに
今回は、多次元尺度構成法により作成したマップを使って、NBAプレイヤー間のスタッツにおける類似性を確認していきました。
作成されたマップを確認する際には、等高線の形式で表現されたヒートマップを使いながら、マップ上の各プレイヤーの配置を解釈していきました。
各プレイヤー間の類似性のベースとなるスタッツをFour factorsに変えたり、分析の対象をチーム単位に変えたりして、改めて分析をしてみても良いかと思います。
なお、本記事は、記事の最後に紹介している書籍を参考にして作成しています。
それでは、今回のトラッシュトークは以上です。
【参考書籍】
Paola Zuccolotto and Marica Manisera (2020), Basketball Data Science – with Applications in R. Chapman and Hall/CRC. ISBN 9781138600799.
※本書籍の紹介記事を書いていますので、よろしければご参考ください。
永田 靖、棟近 雅彦(2001)「多変量解析法入門」サイエンス社.
Kruskal, J.B. (1964), Multidimensional scaling by optimizing goodness of fit to a nonmetric hypothesis, Psychometrika, Vol. 29, p1–27.

