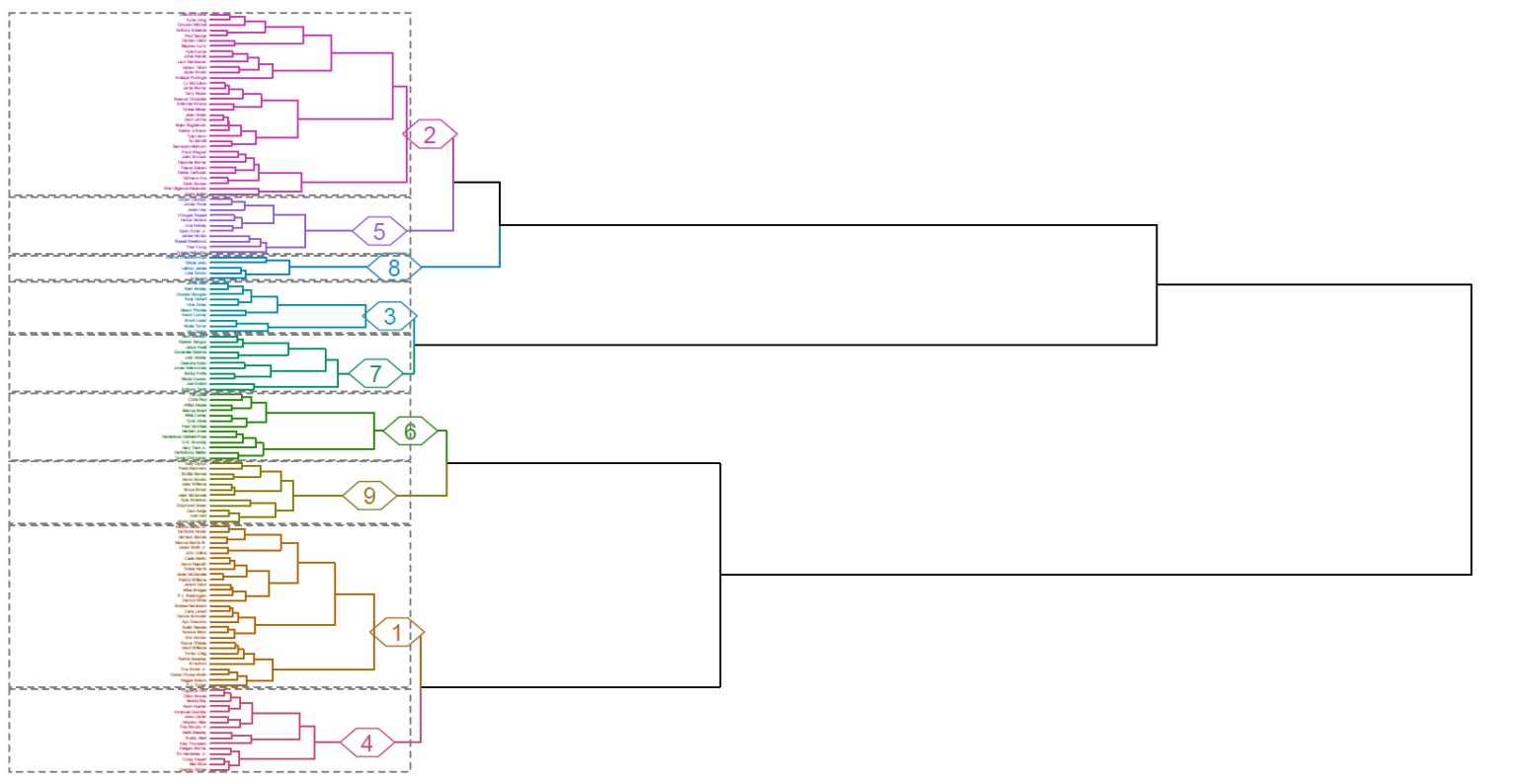
今回は、2022-23レギュラーシーズンにおける8つのスタッツを用いて、ウォード法による階層的クラスター分析によるNBAプレイヤーのグループ分けを行いたいと思います。
使用する統計ソフトはR、データは2022-23レギュラーシーズンのPbox(過去記事参照)を使用します。
まずは、今回のクラスター分析で使用する変数の内容から確認していきます。
※データ分析を実践する際に参考にしている書籍『Basketball Data Science: With Applications in R』の紹介記事も書きましたので、よろしければご確認ください。

分析に使用する変数<PTS、P2M、P3M、DREB、AST、TOV、STL、BLK>
今回のクラスター分析では、NBA2022-23レギュラーシーズンにおける下記の8つの変数を使用します。
- PTS : 獲得点数
- P2M : 2Pシュート成功数
- P3M : 3Pシュート成功数
- DREB:ディフェンスリバウンド数
- AST : アシスト数
- TOV : ターンオーバー数
- STL : スティール数
- BLK : ブロック数
上記の8変数に関しては、出場時間1MIN(分)あたりの数値に変換したものを使用しており、プレイヤーについては、MINが1,800MIN以上のプレイヤー(総数144名)を抽出しています。
なお、クラスター分析を実行する際には、すべてのデータに対して標準化の処理が行われます。
標準化の処理を変数に施して分析を進めた過去記事もありますので、よろしければ下記もあわせてご参考ください。

上記の変数を作成するコマンドは、下記のとおりです。
> library(BasketballAnalyzeR) #パッケージBasketballAnalyzeRの読み込み
> Pbox2223 <- read.csv(file="Pbox_2223.csv") # Pbox2223の読み込み
> attach(Pbox2223) #attach()でPbox2223を指定
> data2223 <- data.frame(PTS, P2M, P3M, DREB, AST, TOV, STL, BLK)/MIN #各スタッツのMINあたりの数値をdata.frame()でまとめてdata2223に格納
> detach(Pbox2223) #detach()でPbox2223を指定から外す
> data2223 <- subset(data2223, Pbox2223$MIN>=1800) #data2223から出場時間1800MIN以上のデータを抽出
> ID <- Pbox2223$Player[Pbox2223$MIN>=1800] #Pbox2223から出場時間1800MIN以上のプレイヤーを抽出しIDへ格納続いて、クラスター数の検討を行いたいと思います。
ウォード法による階層的クラスター分析に伴うクラスター数の検討
統計ソフトRのパッケージBasketballAnalyzeRに含まれるhclustering関数では、デフォルトでウォード法による階層的クラスター分析が実行されます。
クラスター分析を実行する前に、ここでは過去記事と同様に指標“BD/TD”を用いて、クラスター数の検討を行っていきます。
なお、クラスター数の検討に使用する指標“BD/TD”については、下記の過去記事で紹介していますので、よろしければご参考ください。

前述した8変数を使って算出したBD/TDのグラフは、下記のようになります。
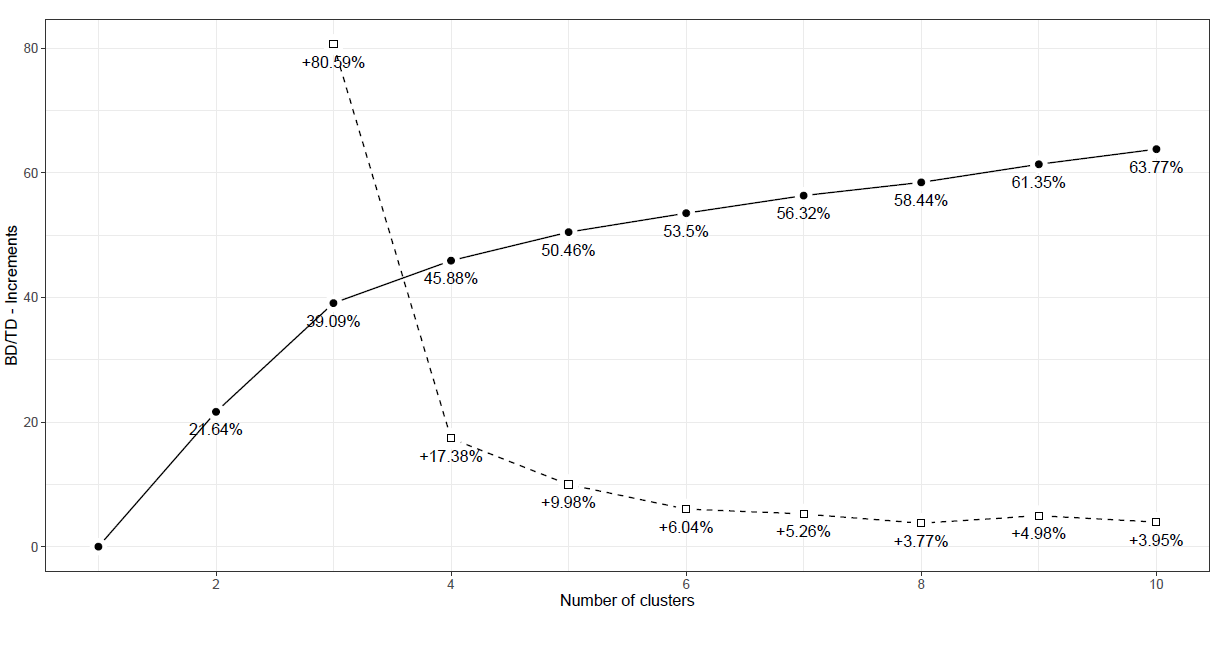
横軸の数値はクラスター数を表し、実線のグラフは各クラスター数におけるBD/TDの値の推移を示しています。(例えば、クラスター数が2の場合のBD/TDは、約21.64%となります。)
破線のグラフは、クラスター数を1つ増やした時のBD/TDの増加率の推移を示しています。(例えば、クラスター数を2→3に増やした時、BD/TDは約80.59%増加することになります。)
参考書籍としている“Paola Zuccolotto and Marica Manisera (2020), Basketball Data Science – with Applications in R.(以下、P. Zuccolotto and M. Manisera (2020)と表記します。)”では、BD/TDの値は50%よりも高いことが望ましく、BD/TDの増加率に関しては、分析対象のデータ数にもよりますが、5%~10%よりも大きい増分となることが望ましいとしています。
作成した上記のグラフを確認すると、クラスター数を7→8に増やした時のBD/TDの増加率が3.77%と一度低い水準に落ち込んではいますが、クラスター数を8→9に増やした時のBD/TDの増加率が約5%であること、また、クラスター数が9の場合のBD/TDの値が61.35%であることから、今回はクラスター数を9に設定して分析を進めていきます。
なお、上記のグラフを出力するコマンドは下記のとおりです。
> hclu1 <- hclustering(data2223)
> plot(hclu1)続いて、前述した2022-23レギュラーシーズンにおける8変数を使って、クラスター分析によるNBAプレイヤーの分類を実行していきます。
クラスター分析によるNBAプレイヤーの分類<ヤニス、ヨキッチ、レブロン、ドンチッチ、ジャ・モラントが同じクラスターに属する>
対象プレイヤー144名に関して9つのクラスターに分類した上で、前述した8変数の平均値をクラスターごとにレーダーチャートで示すと、下記のようになります。
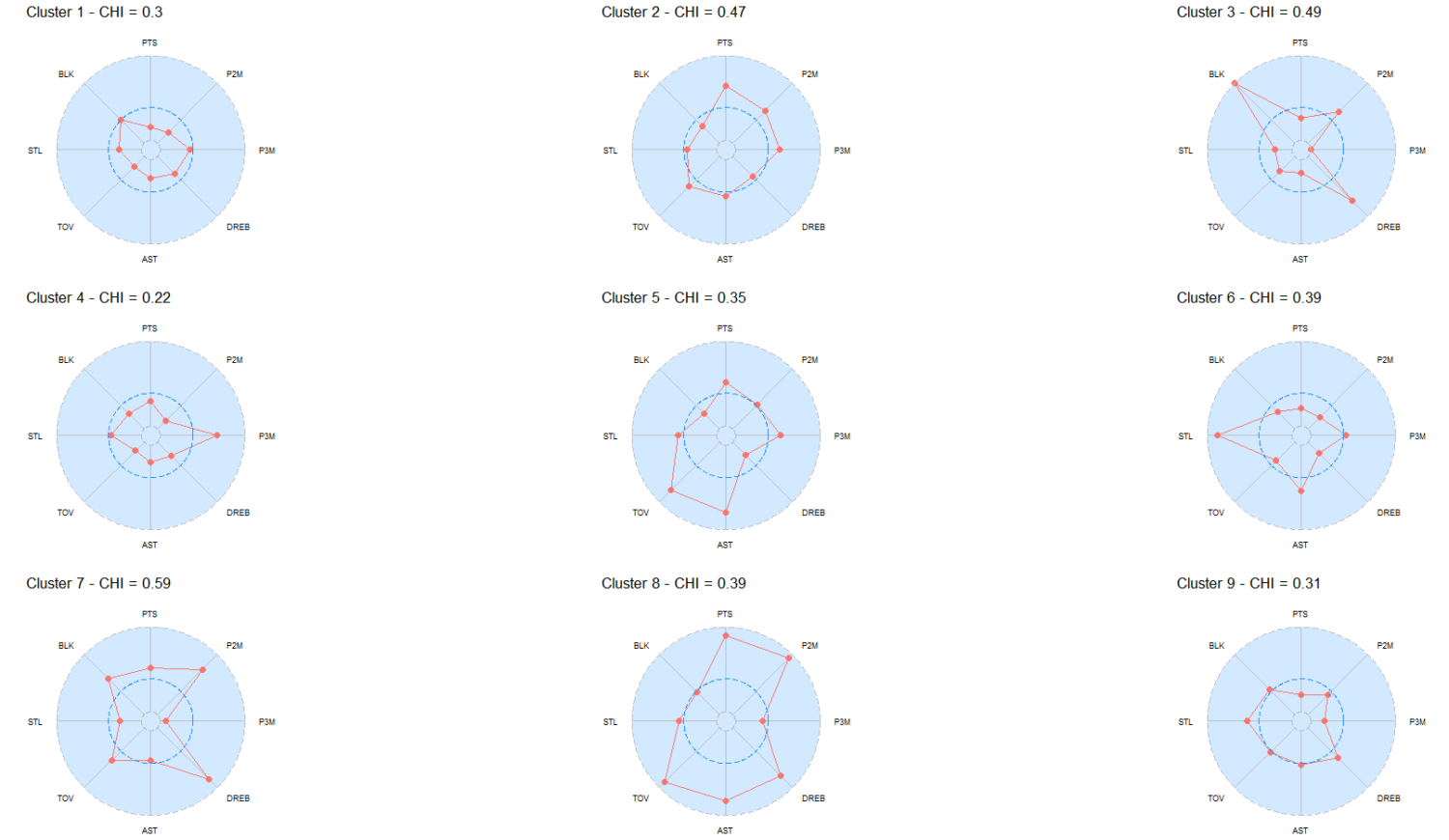
レーダーチャート内にある青色の破線は、2022-23レギュラーシーズンにおける各変数の平均値(前述のとおり標準化の処理がされているため平均0)を表しています。
なお、上記のレーダーチャート内で示されているCHIの数値に関しては、下記の過去記事で紹介していますので、よろしければご参考ください。
上記のレーダーチャート内のCHIの数値を確認すると、クラスター7のCHIの数値が59%を示していますが、参考書籍であるP. Zuccolotto and M. Manisera (2020)では、CHIの数値が50%以下となっていることが望ましいとされているため、今回のクラスター7の結果に関しては、参考値扱いとして分析を進めていきたいと思います。
また、今回のクラスター分析につき、クラスター形成過程を表すデンドログラムを下記に示します。
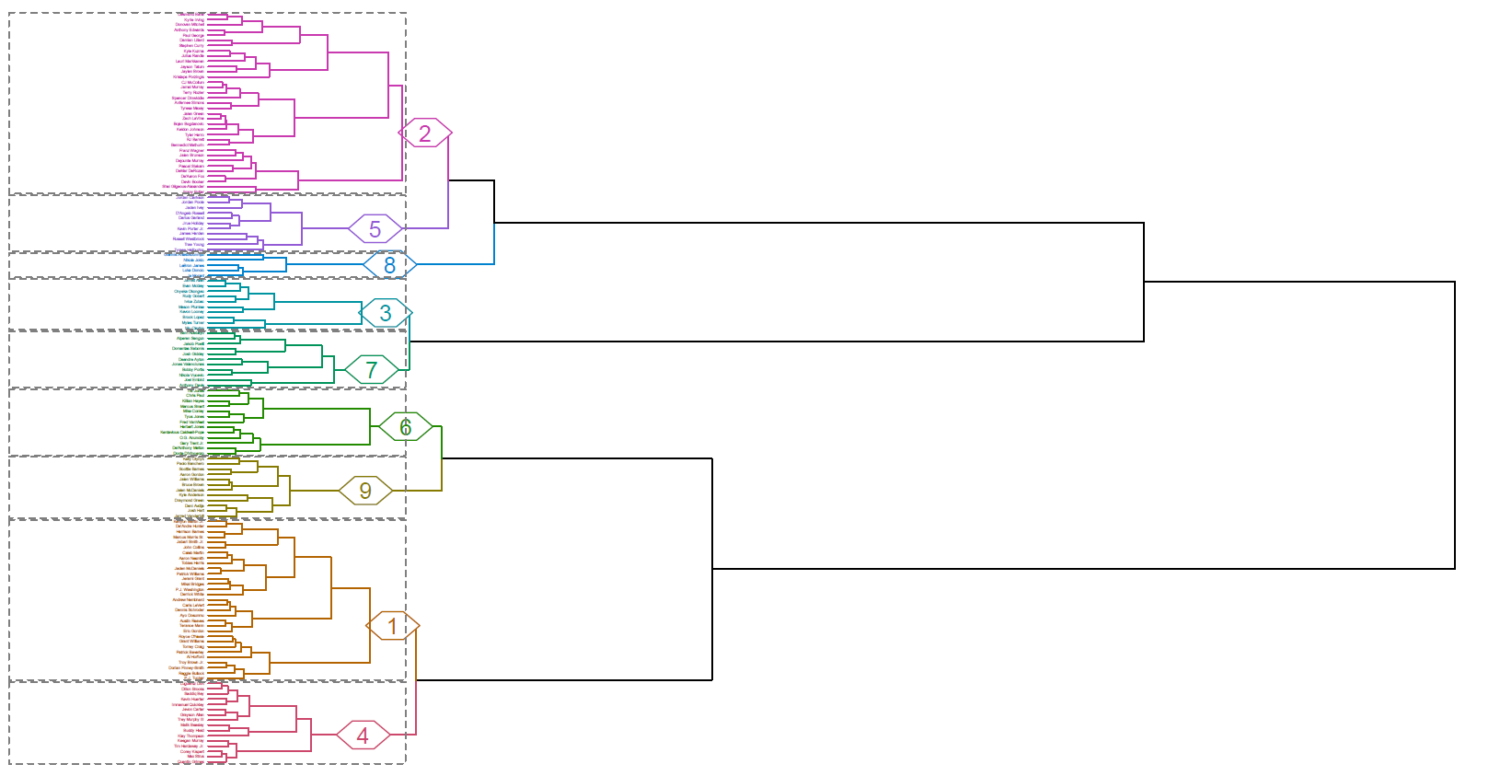
上記のデンドログラムの表示については、144名のプレイヤーが列挙されていることによりプレイヤー名の判別が困難になっているため、各クラスターに所属しているプレイヤー名を確認する場合は、こちらから直接PDFファイルをご確認ください。
上記のレーダーチャートとデンドログラムを考慮すると、NBA2022-23レギュラーシーズンにおけるNBAプレイヤーが所属する9つのクラスターについては、下記のような特徴を読み取ることが出来ます。(※全プレイヤーではなく、2022-23レギュラーシーズンにおける試合出場時間が1,800MIN以上のプレイヤー144名を対象とした特徴となります。)
- クラスター1:対象プレイヤー間で比較した結果、全てのスタッツで平均以下の水準となっているプレイヤーが主に属する。
- クラスター2:獲得点数が比較的多く、2Pシュートと3Pシュートの両方で得点を重ねるプレイヤーが主に属する。(所属プレイヤー:カイリー・アービング、デイミアン・リラード、ステフィン・カリー、ジェイソン・テイタムなど)
- クラスター3:ディフェンスリバウンドとブロックに強みを持ち、2Pシュートに関しても平均以上の水準に達しているプレイヤーが主に属する。(所属プレイヤー:ルディ・ゴベア、ケヴォン・ルーニー、ブルック・ロペス、マイルズ・ターナーなど)
- クラスター4:3Pシュートに重点を置いているプレイヤーが主に属する。(所属プレイヤー:ケビン・ハーター、グレイソン・アレン、クレイ・トンプソン、キーガン・マレーなど)
- クラスター5:アシストを量産し、3Pシュートと得点力に関しても平均以上の水準に達しているプレイヤーが主に属する。ボールをコントロールする機会が多いためかターンオーバーも多い。(所属プレイヤー:ドリュー・ホリデー、ジェームズ・ハーデン、トレイ・ヤング、タイリース・ハリバートンなど)
- クラスター6:スティールが突出して多く、アシストに関しても平均以上の水準に達していることから、攻守両面で堅実にチームに貢献するプレイヤーが主に属する。(所属プレイヤー:クリス・ポール、マーカス・スマート、フレッド・バンブリート、K.コールドウェルポープなど)
- クラスター7:2Pシュート、ディフェンスリバウンド、ブロックで好成績を残し、獲得点数も比較的多いことから、攻守においてチームの柱となっているプレイヤーが主に属する。(所属プレイヤー:バム・アデバヨ、ドマンタス・サボニス、ジョエル・エンビード、アンソニー・デイビスなど)※CHIの数値が50%超のため今回は参考値扱い。
- クラスター8:3Pシュート、スティール、ブロックを除くすべてのスタッツで最高水準の成績を残しているプレイヤーが主に属する。(所属プレイヤー:ヤニス・アデトクンボ、ニコラ・ヨキッチ、レブロン・ジェームズ、ルカ・ドンチッチ、ジャ・モラント)
- クラスター9:ディフェンスリバウンド、アシスト、スティール、ブロックなど得点力以外の側面からチームを支えるプレイヤーが主に属する。(所属プレイヤー:パオロ・バンケロ、アーロン・ゴードン、ブルース・ブラウン、ドレイモンド・グリーンなど)
なお、上記のクラスター分析を実行するコマンドは、下記のとおりです。
> hclu2 <- hclustering(data2223, labels=ID, k=9)
> plot(hclu2, profiles=TRUE) #レーダーチャートを出力
> plot(hclu2, rect=TRUE, colored.branches=TRUE, cex.labels=0.2) #デンドログラムを出力おわりに
今回は、ウォード法による階層的クラスター分析を用いて、2022-23レギュラーシーズンにおけるNBAプレイヤーのグループ分けを行いました。
グループ分けの際には、使用した8変数につきクラスターごとの平均値を考慮することで、対象プレイヤーが分類された各クラスターの特徴を把握することが出来ました。
今回は2022-23レギュラーシーズンのみの分析となりましたが、複数シーズンの分析結果を比較することで、特定プレイヤーのチーム内(あるいは移籍チーム先)における役割の変遷などを確認することも可能かと思います。
なお、本記事は、記事の最後に紹介している書籍を参考にして作成しています。
それでは、今回のトラッシュトークは以上です。
【参考書籍】
Paola Zuccolotto and Marica Manisera (2020), Basketball Data Science – with Applications in R. Chapman and Hall/CRC. ISBN 9781138600799.
※本書籍の紹介記事を書いていますので、よろしければご参考ください。
川端一光、岩間徳兼、鈴木雅之(2018)『Rによる多変量解析入門ーデータ分析の実践と理論ー』オーム社.
永田 靖、棟近 雅彦(2001)「多変量解析法入門」サイエンス社.
【参考ウェブサイト】
統計WEB.“7-4. 階層型クラスター分析1”.統計学の時間.https://bellcurve.jp/statistics/course/27301.html,(参照2023-12-07).
統計WEB.“7-5. 階層型クラスター分析2”.統計学の時間.https://bellcurve.jp/statistics/course/27301.html,(参照2023-12-07).

